



 Google et l’université de Stanford travaillent sur un algorithme capable de décrire le contenu de nos images et la nature d’une scène.
Google et l’université de Stanford travaillent sur un algorithme capable de décrire le contenu de nos images et la nature d’une scène.
Le logiciel de reconnaissance d’images élaboré est capable de reconnaître une scène, d’en analyser le contenu en déterminant les relations qu’ont les éléments entre eux et d’en rédiger une description, aussi bien sur des photos que sur des vidéos. C’est une nouvelle étape franchie dans le domaine de la reconnaissance d’images, alors que les algorithmes étaient déjà capables de reconnaître la nature d’un objet.

Pour ce faire, Google a comparé les descriptions de scènes fournies par des personnes participantes à l’étude à celles de son logiciel. Le système associe ainsi des images à des phrases : les composants de l’image sont identifiés et associés à des mots, ensuite l’outil essaie de construire des phrases cohérentes par rapport aux images. Les descriptions créées par le logiciel seraient particulièrement convaincantes, même si quelques erreurs subsistent.
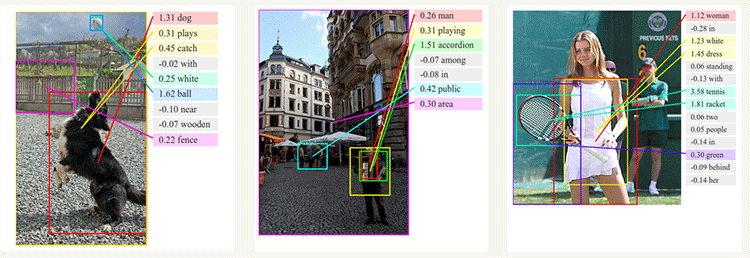

La recherche sémantique devrait permettre de mieux décrire et donc de mieux référencer les milliards de médias indexés par Google sur le moteur de recherche ou sur YouTube.
Le service pourrait aussi à l’avenir être utilisé pour décrire des scènes aux malvoyants.

Sources :
http://cs.stanford.edu/people/karpathy/deepimagesent/
http://googleresearch.blogspot.fr/2014/11/a-picture-is-worth-thousand-coherent.html
